I’ve spent a fair amount of years with Terraform now, and it’s come along way since the 0.8 days. In the same way, organisations have made significant progress in their journeys to the Cloud. Because of this, and having worked with a number of such businesses, I wanted to talk about one of the key topics when it comes to Terraform – what does good look like? Looking back, the code I write today is a far cry (read: leagues better) than the code I wrote in 2017, and with that in mind, here are some of my insights.
When starting out with Terraform it’s very easy to get caught in a trap of this “shiny new tool that’s going to solve all your problems”. Without proper planning before writing code, more often than not you’ll find yourself mired in tech debt, and over time, that debt slows you down to a crawl when you inevitably have to re-write it to get it to a place where it’s easily maintainable.
Code style & consistency
Like any new process, taking the time to define what “good” looks like is paramount. A good place to define a style guide to ensure consistency in code from the start. Standard best-practice ideas such as:
Resource block format
Resource block names should only consist of underscores. This keeps them consistent with the resource identifiers of the provider that also use underscores.
resource "azurerm_resource_group" "my_first_resource_group"Resource attributes
Resource attribute names should separate words with hyphens.
Separate words with hyphens in resource attribute names. This helps readability, while still conforming to the constraints of names in Azure. There are exceptions though – like Storage accounts, which must be a single alphanumeric string.
resource "azurerm_resource_group" "my_first_resource_group" {
name = "my-first-resource-group"
location = "UK South"
}Make liberal use of Terraform fmt
terraform fmt is a built-in function of the Terraform binary. It will format your code in a consistent manner, ensuring your code adheres to some of the standards set out by Hashicorp – for example, aligning equals (=) signs on your resource blocks and aligning tabs consistently. I recommended to always run terraform fmt before committing code to a repo. You can automate this to an extent by using pre-commit hooks – but these are out of scope of the article
Variables & params
Ensure you have descriptively named variables, and always include a description for the variable. Setting appropriate type constraints helps to validate inputs, protecting against mistakenly entering a letter where you would expect a number input. A good variable would look like this:
variable "primary_region" {
type = string
description = "The region to deploy the resources to"
default = "UK South"
} Folder structure & files
Descriptively name your files
File names are the first thing – apart from the readme – that you’ll notice in a repo. Enforcing a common format across your codebase keeps repos tidy and gives your fellow engineers insight into what’s been deployed for a given project.
The documentation at Hashicorp recommends a file structure as seen in the below table:
| File name | Description |
| backend.tf | Contains the backend configuration – where your state lives |
| main.tf | Where all resources and datasources are defined |
| outputs.tf | Containing outputs from resources to be used elsewhere, or to easily read on the CLI. |
| providers.tf | Containing all Provider blocks and Provider configuration |
| terraform.tf | Contains the terraform block, defining the Terraform version and Providers to use |
| variables.tf | For variable blocks used throughout the code |
| locals.tf | For local variables & values |
While this is a good starting point, I prefer two changes to the suggested conventions:
- Merging the
providers.tfandbackend.tfinto a singleterraform.tffile to reduce file bloat - Defining files with appropriate names for the resources contained within, for example –
- network.tf containing VNets/VPCs & subnets
- nsgs.tf containing NSG definitions
- routes.tf containing route tables & routes
- individually named files for virtual machines, e.g. print-server.tf, domain-controller.tf
Planning your tfvars files
.tfvars files are integral to detailing environment specific parameters. When working in multi-region, multi-environment projects, think about organising these files into appropriate folders. An example of this that I’ve used repeatedly looks like this –
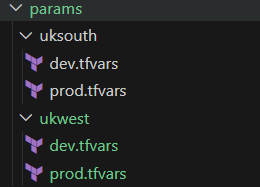
This isn’t a hard and fast rule; form the structure around your business requirements, for example – some organisations group by environment then region
Avoid creating monoliths
Monoliths in Terraform (or “Terraliths”) usually come about when files become too large to effectively glean the purpose of the file – and this is why I recommend splitting resources between appropriately named files versus the single main.tf suggested by the Hashicorp documentation. I’ve seen the gauge for digestible file sizes vary by organisation, and again there is no hard and fast rule. Try to be sensible and if it makes sense to split some files – e.g. chunking one long list of NSG rules into multiple files – then feel free to do so. Your PR reviewers will thank you!
Terraform modules
Terraform module composition
Modules should be used to group together sets of resources that fulfil the same role or function. A good example of this is a virtual machine. Think of the components required for a VM in Azure –
- Virtual Machine
- NIC
- Disks
- VM extensions
Grouping these resources into a module enables definition of the virtual machine and all the resources via a common set of parameters. Bear in mind, modules with single resources are an anti-pattern.
Terraform module naming
It’s a good idea to prefix your modules with “terraform” or “tf” to indicate they are modules. A consistent prefix also helps keep them together in the list of repos. Name them as descriptively as possible for the “purpose” they fulfil, some examples are:
- tf-azure-windows-virtual-machine
- tf-azure-app-service
- tf-azure-api-management
- tf-azure-data-pipeline
Terraform module versioning
When distributing modules, use Semantic Versioning to tag your module versions. Semantic versioning is a way of numbering software releases to clearly indicate the type of changes made. Versions follow the format MAJOR.MINOR.PATCH, where each part signals the impact of the update. This helps developers and users understand whether an upgrade may break compatibility, add features, or just fix bugs.

Terraform & Provider versions
Version Constraint Operators
Terraform & provider versions should be pinned everywhere using the available constraints shown in the table below. The most common operator I use is the Pessimistic Operator on minor version numbers, as this allows my versions to upgrade within all minor versions released up to the next major version. This is especially useful in template repos, where if a new version releases, I want the new project built from the template repo to use the latest possible versions.
| Operator | Description |
| = | Only the exact version specified will be used |
| != | Exclude this version number |
> | Use a version greater than this number |
>= | Use a version greater than or equal to this number |
< | Use a version less than this number |
<= | Use a version less than or equal to this number |
| ~> | Called the “Pessimistic” operator. This allows only the end digit(s) to increment. For example, ~> 1.2 will allow the minor version 2 to increment, but not increment past the major version of 1 |
Terraform.lock.hcl file
The terraform.lock.hcl file is instrumental in maintaining consistent versions once a Terraform codebase has been initialised. This file prevents different developers from initialising their code to a different version than each other which can cause conflicts and has potential to be very messy to fix after the fact.
The Terraform lock file should always be committed to source control.
Terraform state
Terraform state is the source of truth for IaC. The state file contains all of the resources deployed with Terraform, and the links between resources. If a manual change is made via the portal, those changes will not be updated in Terraform until the IaC is updated to match. Where differences are noted, the concept is called “state drift”.
When storing remote Terraform state (e.g. state files stored somewhere in the cloud, in a Storage Account or S3 Bucket, keeping the file as secure as possible is key to ensuring integrity of your infrastructure (and IaC). Private, versioned storage systems, and clearly segregated structures ensure blast radius for any user error or malicious actions are mitigated. I recommend creating containers per region – or in the case of Azure – per Subscription as a basic starting point.
Closing comments
I hope you enjoyed the read and have a few takeaways from this. If you’d like to know more about any of the concepts in this post, reach out to me via LinkedIn or let me know in the comments below.
Outstanding read thank you!